Written by: Igor
Published: December 2025
A data engineering service builds the digital plumbing to connect and clean up your raw data. It’s the system that takes messy information from sources like Stripe, HubSpot, and your production databases and turns it into a clean, reliable asset. This foundational work is what makes your AI and analytics ambitions a reality. Without it, your most valuable data stays trapped, messy, and unusable.
This guide gives you a clear framework for evaluating and implementing a data engineering service, moving from a state of data chaos to one of total clarity.
Key takeaways
- Foundation first: You can't build reliable AI on messy data. A data engineering service creates the stable foundation needed for trustworthy analytics and machine learning models.
- Start small: Don't try to fix everything at once. Begin with a small pilot project focused on a single, high-impact business problem to prove value quickly.
- Measure outcomes: The right partner commits to clear key performance indicators (KPIs) like data freshness and pipeline uptime, not just vague technical promises.
- Think long-term: Choose a partner who designs for scale from day one to avoid costly re-architecture projects down the road.
Your data is messy, but your AI ambitions are huge
Let’s be direct. Your business is sitting on a goldmine of data, but right now, it’s a chaotic mess. This is the single biggest blocker to getting any real AI initiative off the ground. You can't build trustworthy AI models or pull accurate business insights from information that's inconsistent, siloed, and full of errors.
This is exactly where a data engineering service gives you a competitive edge.
Instead of another technical cost, view it as the essential infrastructure that turns a major liability into your company’s most powerful asset. According to McKinsey, companies that successfully scale AI report profit margins that are 3 to 15 percentage points higher than the industry average. A specialized service builds the pipelines to make sure the data feeding your analytics and AI models is clean, consistent, and dependable.
The cost of doing nothing
Ignoring your data foundation has real consequences. Data scientists spend up to 80% of their time just cleaning and preparing data, according to multiple industry surveys. That’s a massive drain on your most expensive technical talent, and it directly delays product launches and critical strategic decisions.
The problem only gets worse as your data volumes grow. Without a scalable system, you’re looking at:
- Unreliable analytics: Poor data quality leads to flawed reports and, ultimately, bad business decisions.
- Failed AI projects: The old "garbage in, garbage out" rule is ruthless. Messy data kills AI models before they even have a chance to learn.
- Operational bottlenecks: Your teams are stuck manually correcting data errors instead of focusing on growth and innovation.
To get a handle on your information and move toward your AI goals, you first have to grasp the fundamentals of data transformation. Understanding concepts like What Is Data Parsing And How It Enables Better RAG Systems is a great first step.
Before you can build, you need to know where you stand today. Running an initial audit can uncover critical gaps in your current setup. Our guide on conducting an AI readiness assessment is designed to help you pinpoint quick wins and identify potential risks.
What a modern data engineering service actually does
Let's cut through the jargon. A modern data engineering service isn't just about managing databases. It’s about building the digital factory your business needs to turn raw, messy data into a high-value asset. It's less of a cost center and more like your company's central nervous system for information.
The core job is to design, build, and maintain the systems that collect, clean, and organize all your data. A good service provider takes on the heavy lifting so your data scientists aren't stuck spending up to 80% of their time just wrestling with data prep instead of finding insights.
This visual shows the powerful transformation data engineering makes possible, turning chaotic raw inputs into a structured foundation for smart business decisions.
This process is the essential bridge between the data you have and the insights you need to drive growth. To understand what you're buying, it helps to break down the key functions using a simple analogy: building a supply chain for your data.
Data ingestion and ETL/ELT
First, you collect your raw materials. Data ingestion is the process of pulling information from all your different sources-Stripe for payments, HubSpot for CRM data, your app's database, third-party APIs. A data engineering service sets up automated connectors to gather all of this reliably.
Once the raw materials arrive, they need to be processed. This is where ETL (Extract, Transform, Load) or its modern cousin, ELT (Extract, Load, Transform), comes in.
- Extract: Pulling the data from its original source.
- Transform: Cleaning, standardizing, and structuring the data. This might mean converting date formats, weeding out duplicate entries, or joining customer data from two different systems into one unified view.
- Load: Moving the newly processed data into a central storage system, like a data warehouse.
The only real difference between ETL and ELT is the order of operations. Modern setups often use ELT, loading raw data into a powerful warehouse first and transforming it later for more flexibility. The goal is the same: convert inconsistent raw data into a clean, standardized format ready for analysis.
Data warehousing and data pipelines
All that processed data needs a home. A data warehouse (think tools like Snowflake, BigQuery, or Redshift) is an organized, secure facility where your analytics-ready data is stored. Unlike a typical database designed to run an application, a data warehouse is optimized for running fast, complex queries.
A data pipeline is the automated workflow that moves data from Point A to Point B, including all the ingestion and transformation steps. Think of it as the automated conveyor belt in your data factory. A good data engineering service builds these pipelines to be resilient and observable, so you always know if data is flowing correctly and on time.
Orchestration and governance
With multiple data pipelines running, you need an air traffic controller. That's where orchestration comes in. As this guide to orchestration in data engineering explains, this involves using tools like Airflow or Dagster to manage dependencies, schedule jobs, handle errors, and make sure everything runs in the right order.
Finally, data governance sets the rules of the road for your data. It answers critical questions like:
- Who has access to what data?
- How is data quality measured and maintained?
- How do we ensure compliance with regulations like GDPR or CCPA?
A service provider implements the tools and processes to enforce these rules, ensuring your data is not only useful but also secure and compliant.
Why you can't scale AI without a solid data foundation
Every founder wants to build AI into their product, but many jump straight to hiring data scientists without realizing they’ve skipped the most critical step. Building a powerful AI model on messy, unreliable data is like trying to construct a skyscraper on a foundation of sand. It’s not a matter of if it will collapse, but when.
The old saying "garbage in, garbage out" has never been more true. Your AI is only as smart as the data it learns from. This is where a professional data engineering service becomes non-negotiable-it’s the only way to ensure the data feeding your models is clean, consistent, and trustworthy.

From fragile scripts to resilient systems
Early-stage companies often start with a patchwork of manual processes and simple scripts to move data. For a little while, it works. But as your data volumes grow, those fragile systems crack.
A well-architected data foundation, built by a dedicated service, is designed for scale from day one. It’s built to handle exponential growth in data volume and complexity without buckling. This resilience is what separates companies that successfully bake AI into their DNA from those stuck in endless pilot projects.
Think about the real-world consequences:
- Inaccurate predictions: If sales data is a mess, an AI forecasting model will churn out wrong numbers, leading to costly mistakes in inventory and resource planning.
- Biased outcomes: Incomplete or skewed customer data can train a personalization engine to ignore entire segments of your audience, tanking engagement.
- Security risks: Without proper governance, you can’t prove where your data came from or who has touched it, creating massive compliance and legal headaches.
This isn't just a technical problem; it's a fundamental business risk.
Empowering your data science team to deliver value
The hidden cost of poor data infrastructure is wasted talent. By providing clean, analytics-ready data on tap, a solid data engineering service frees up your data science team to focus on what they were hired to do: create value. They can experiment faster, iterate on models more quickly, and deploy new AI-powered features in weeks instead of months.
Example: E-commerce forecasting
A mid-sized e-commerce company was battling inaccurate sales forecasts. Their data was scattered across Shopify, Google Analytics, and an internal inventory system. Their data team was burning hours manually merging spreadsheets, leaving no time for analysis.
They brought in a data engineering service to build an automated pipeline. Here is a simple workflow checklist of what the service provided:
- Connect: Set up automated connectors to ingest data from all three sources every hour.
- Standardize: Clean and unify the information, creating a single view of customers and products.
- Load: Move the pristine data into a central data warehouse.
- Enable: Provide access for the data science team to the clean data.
The results were immediate. Armed with a reliable dataset, the data science team built a new forecasting model that improved accuracy by over 30%. This directly led to smarter inventory management, fewer stockouts, and a significant lift in revenue.
How to choose the right data engineering partner
Picking the right partner for your data engineering services is a critical business move. The wrong choice can leave you with brittle systems, cost overruns, and a data foundation that crumbles when you need it most. The right partner becomes an extension of your team, building the reliable infrastructure that fuels your growth.
Focus on the business outcomes you need. A great partner should have no trouble answering direct questions about transparency, performance, and cost. This section is a practical checklist to help you find a provider that fits your needs and long-term vision.
Audit-ready transparency
You can’t afford a “black box” data system. You must be able to prove where your data came from, how it was transformed, and who has access to it. This isn’t just about compliance; it's about building fundamental trust in your data.
When vetting a partner, get specific:
- Data lineage: Can they show you a clear, auditable trail for every piece of data? You need to see its entire journey for debugging and compliance.
- Access controls: How do they manage who sees what? They should have a rock-solid framework for role-based access.
- Documentation: Is their documentation clear and consistently updated? Without it, you’re setting yourself up for a massive dependency risk.
A provider that prioritizes transparency builds systems you can manage and trust.
Performance guarantees and KPIs
Vague promises of "high performance" are a red flag. A professional data engineering service should commit to specific key performance indicators (KPIs) that prove your data infrastructure is healthy and reliable. Their success should be measurable.
Before you sign anything, agree on the core metrics that matter:
- Data freshness: How up-to-date will the data be? Get a specific commitment, like "data will be refreshed every 60 minutes."
- Pipeline uptime: What is their service level agreement (SLA)? For production systems, a target of 99.9% is a reasonable expectation.
- Data quality score: How will they measure accuracy? This could be a score based on the percentage of records that pass validation checks.
These metrics shift the conversation from tech talk to business value. Exploring options like big data consulting can provide a solid framework for these early conversations.
Comparing data engineering service provider models
Choosing the right partner also means understanding the different types of providers. A large enterprise has different needs than a fast-moving startup. This table breaks down the common options.
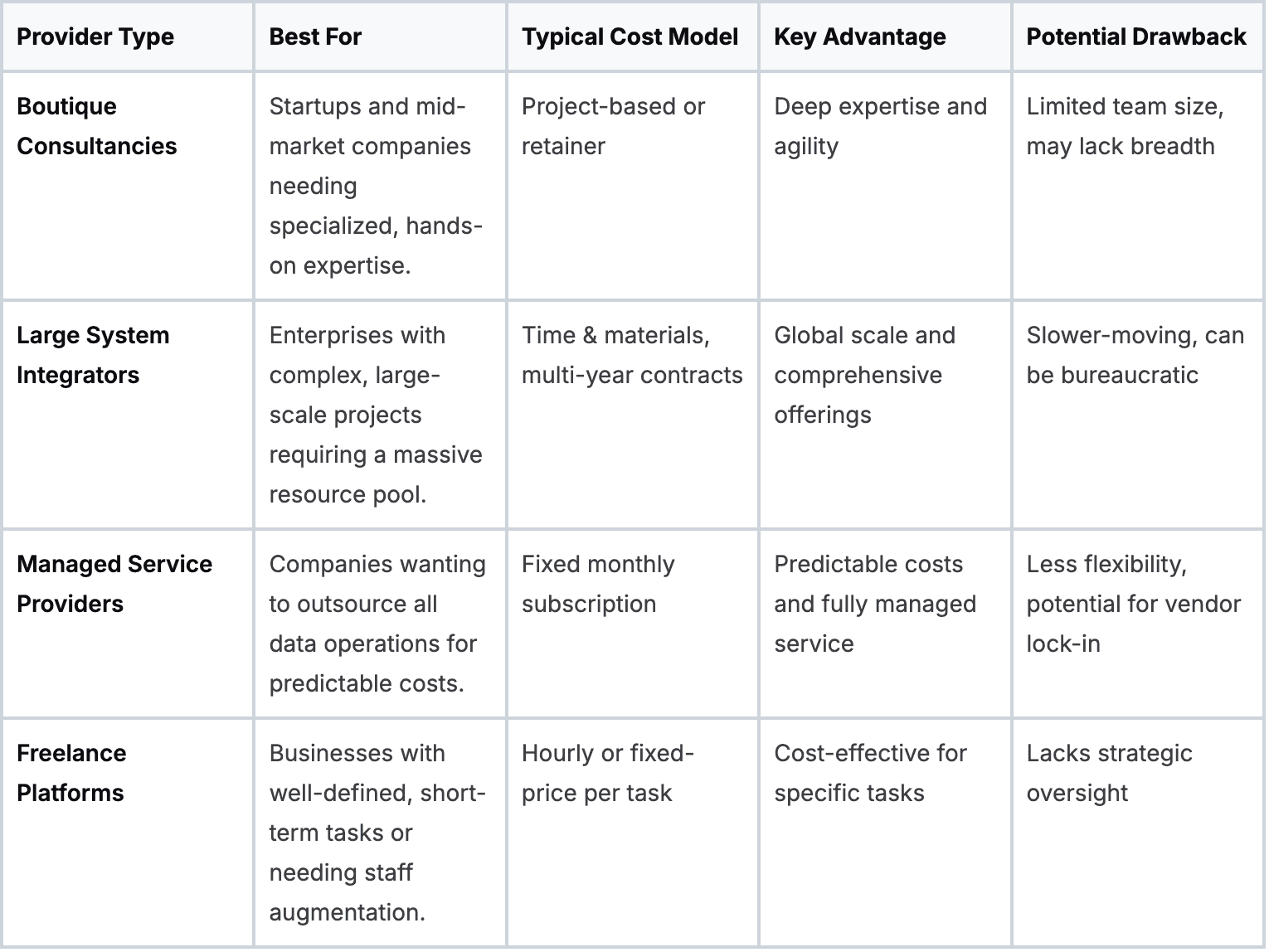
A boutique firm might be perfect for building an innovative MVP, while a large integrator is better suited for a global system migration. Use this as a guide to focus on partners whose model aligns with your business reality.
Future-proof architecture
Your business is going to grow, and your data infrastructure must be ready. A solution that works perfectly today could become a bottleneck in 12-18 months. A forward-thinking partner designs for scalability from day one, helping you avoid a costly "rip and replace" project later.
As Atos points out, modern data solutions must be built for extreme scalability and adaptability, especially with the demands of GenAI. You should ask them:
- Scalability: How does your proposed architecture handle a 10x or 100x increase in data volume?
- Modularity: Is the system built with components that can be easily upgraded or swapped out as better technologies emerge?
- Extensibility: How easily can we add new data sources or connect new tools without re-engineering the entire system?
A partner who obsesses over future-proofing is investing in your long-term success.
Clear and predictable cost models
Finally, there should be zero mystery in the cost model. The last thing you want is a surprise cloud bill that blows up the budget. A good partner works with you to design a cost-effective solution and gives you clear visibility into ongoing expenses.
Scrutinize their pricing structure. No matter the model-fixed-price, monthly retainers, or consumption-based-demand clarity on what drives costs. A partner who helps you understand and manage these costs is a true ally.
Your roadmap from messy data to production-ready insights
Trying to turn chaotic data into something useful can feel impossible. The biggest mistake is trying to boil the ocean. A smarter approach is to think in phases, focusing on quick wins that build momentum and prove the value of your efforts.
This roadmap breaks the project into four manageable stages. It’s a practical plan for turning a big data problem into a series of achievable milestones, ensuring your investment in a data engineering service starts paying off from day one.
Phase 1: Discovery and audit (Weeks 1-2)
You can't fix what you don't understand. The first step isn't about code; it's about mapping your current data landscape and tying the project to a real business problem.
The goal here is to answer a few critical questions:
- What are our most critical data sources? (e.g., Stripe, HubSpot, production database)
- What's the one business question we can't answer today that would be a game-changer? (e.g., "What is our true customer acquisition cost across all channels?")
- Where are the biggest data quality nightmares? (e.g., duplicate customer records)
A successful discovery phase gives you a clear problem statement and a short list of the specific data needed to solve it.
Phase 2: Pilot project (Weeks 3-6)
With a clear target, it's time to launch a small, high-impact pilot project. This is where you prove the value of data engineering in weeks, not months. The pilot should be laser-focused on solving the single business problem you identified in Phase 1.
A typical pilot project looks like this:
- Connect to 2-3 essential data sources.
- Build one simple, automated data pipeline.
- Create a single, unified dataset to answer your target business question.
- Deliver one key dashboard or report that provides immediate value.
The outcome is a working solution that demonstrates a clear return on investment and makes the business case for a larger build.
Phase 3: Foundational build (Weeks 7-12)
Once the pilot has proven its worth, it's time to build the core infrastructure that will scale. This is where you take the lessons from the pilot and design a resilient, future-proof data foundation. Your data engineering service partner will architect the central data warehouse, set up governance rules, and build the primary data pipelines.
Key activities in this phase include:
- Designing the data warehouse schema.
- Implementing automated data quality checks and monitoring.
- Building reusable pipeline components.
- Establishing security and access control policies.
This phase is about doing the unglamorous but essential work. You're building the bedrock for all of your future AI initiatives. For a deeper look at this process, check out our guide on creating an AI implementation roadmap.
Phase 4: Scale and optimize (Ongoing)
With a solid foundation in place, you can finally move fast. This last phase is a continuous cycle of expanding the platform to new business problems and optimizing its performance. Now you can connect more data sources, build new analytics dashboards, and feed clean data to your machine learning models.
The true measure of a successful data platform isn't its technical complexity, but how quickly it allows you to answer new business questions. This iterative approach ensures your data infrastructure grows alongside your business, constantly delivering value.
The one thing to do next
Your first step isn't a massive project. It's an honest assessment. Identify the single most painful data problem your business faces today-the report you can't build, the question you can't answer. Use that as the starting point for a conversation about a small, focused pilot project. A good data engineering service can turn that one problem into a quick win, building the momentum you need for a truly data-driven future.
We at N² labs can help you move from data chaos to a production-grade AI foundation. Our readiness assessments and focused roadmaps are built to deliver measurable results in weeks, not years. Learn more about how we turn AI concepts into durable ROI.
FAQ
Costs depend on project scope. A small pilot project could start in the low thousands, while building a full-scale platform is a larger investment. A good provider will suggest starting small with a high-impact project to prove the return on investment (ROI). This approach removes risk and builds a solid business case for a bigger commitment.
You don’t have to wait months. While a complete data platform is a long-term goal, a well-scoped pilot project can deliver tangible results in just 4-8 weeks. For example, creating a single dashboard that pulls customer data from Stripe and HubSpot can give your sales and marketing teams immediate, actionable insights. This incremental approach is more effective than a massive "big bang" project.
While software and data engineers share some skills, their core disciplines are different. Software engineers are pros at building applications for users. Data engineers specialize in designing resilient, scalable systems to handle enormous volumes of data. Asking your app developers to build complex data infrastructure often leads to brittle solutions that can't scale. In fact, Gartner points to this as a key reason why so many data projects fail.
Think of it like building a national highway system. Data engineers are the civil engineers who design and construct the highways, bridges, and interchanges. Their job is to ensure a smooth, reliable flow of traffic (data). Data scientists are the expert drivers who use those highways to transport valuable goods-in this case, insights and AI models. Data engineering builds the infrastructure to make data clean and accessible; data science uses that data to run analyses and train models.